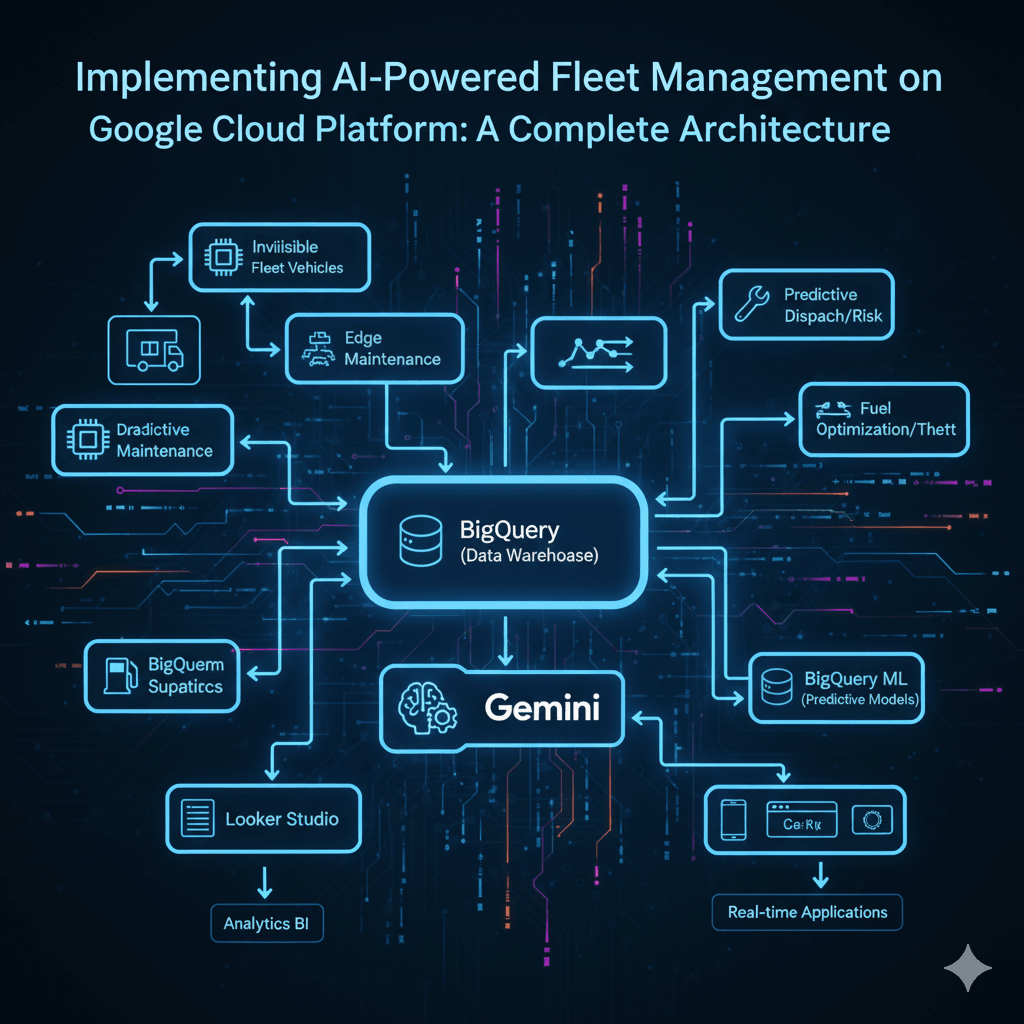



A Comprehensive Guide to Building Intelligent Fleet Operations with GCP's AI Stack
Executive Summary
Modern fleet management faces unprecedented challenges: rising fuel costs, driver safety concerns, maintenance unpredictability, and the constant pressure to optimize routes in real-time. Artificial Intelligence offers transformative solutions to these challenges, and Google Cloud Platform (GCP) provides a robust, unified ecosystem to implement them.
This article presents a complete Proof of Concept (POC) architecture for implementing 10 critical AI capabilities in fleet management using GCP's native services. We'll cover everything from no-code solutions using BigQuery ML to advanced agentic AI with Vertex AI, traditional classification models, and time series forecasting.
What You'll Learn:
Complete GCP architecture for each of the 10 AI use cases
No-code, low-code, and custom ML implementation strategies
Integration patterns between GCP services
Cost optimization strategies
Real-world implementation roadmap
Architecture Overview
High-Level System Architecture
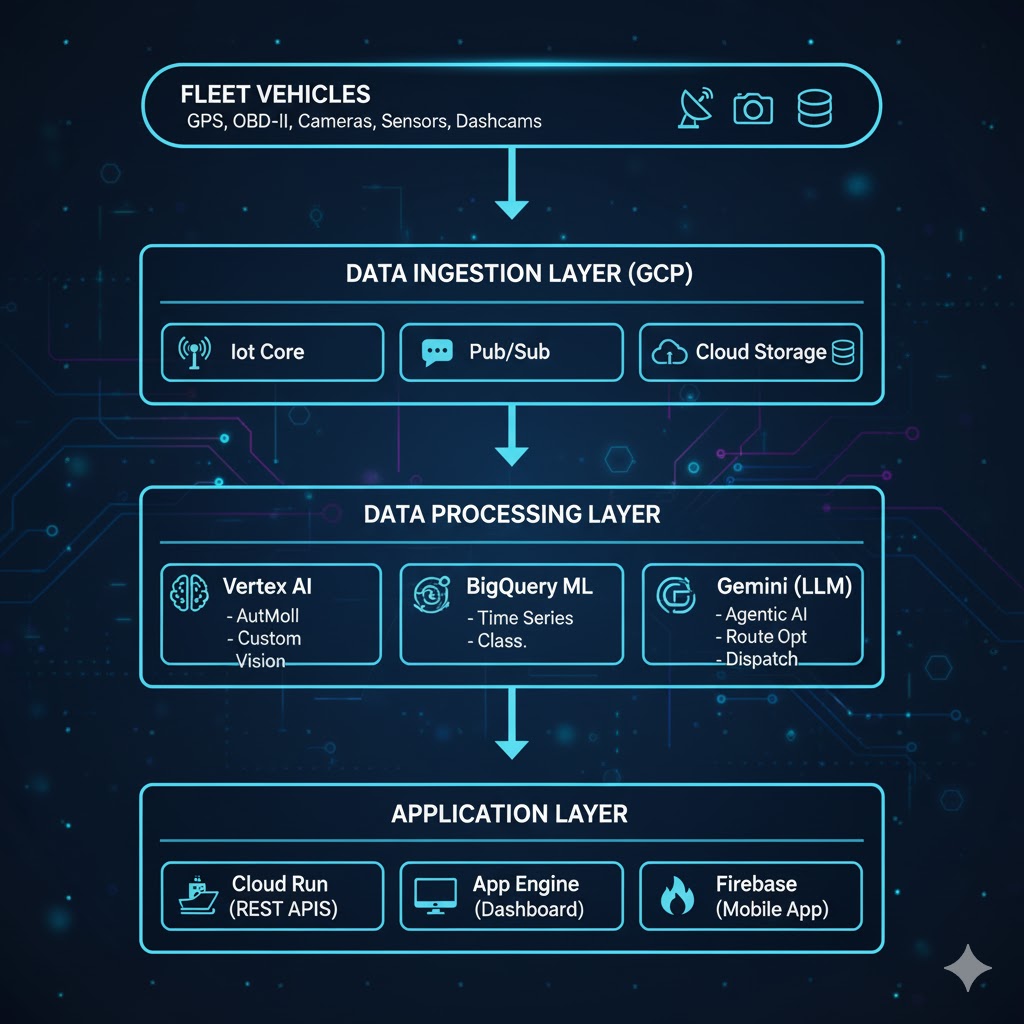
Our GCP-based fleet management AI system consists of five core layers:
Layer | Components | Purpose |
|---|---|---|
1. Data Ingestion Layer | • IoT Core | • Real-time vehicle telemetry |
2. Data Processing Layer | • Dataflow | • Stream processing |
3. AI/ML Layer | • Vertex AI | • Custom ML models |
4. Application Layer | • Cloud Run | • Microservices & REST APIs |
5. Monitoring & Security Layer | • Cloud Monitoring & Logging | • System monitoring & logging |
10 AI Implementation Deep Dives
1. Predictive Maintenance - Time Series Forecasting
Problem: Unplanned vehicle breakdowns cost fleets $500-$800 per incident in lost productivity.
GCP Solution Architecture:
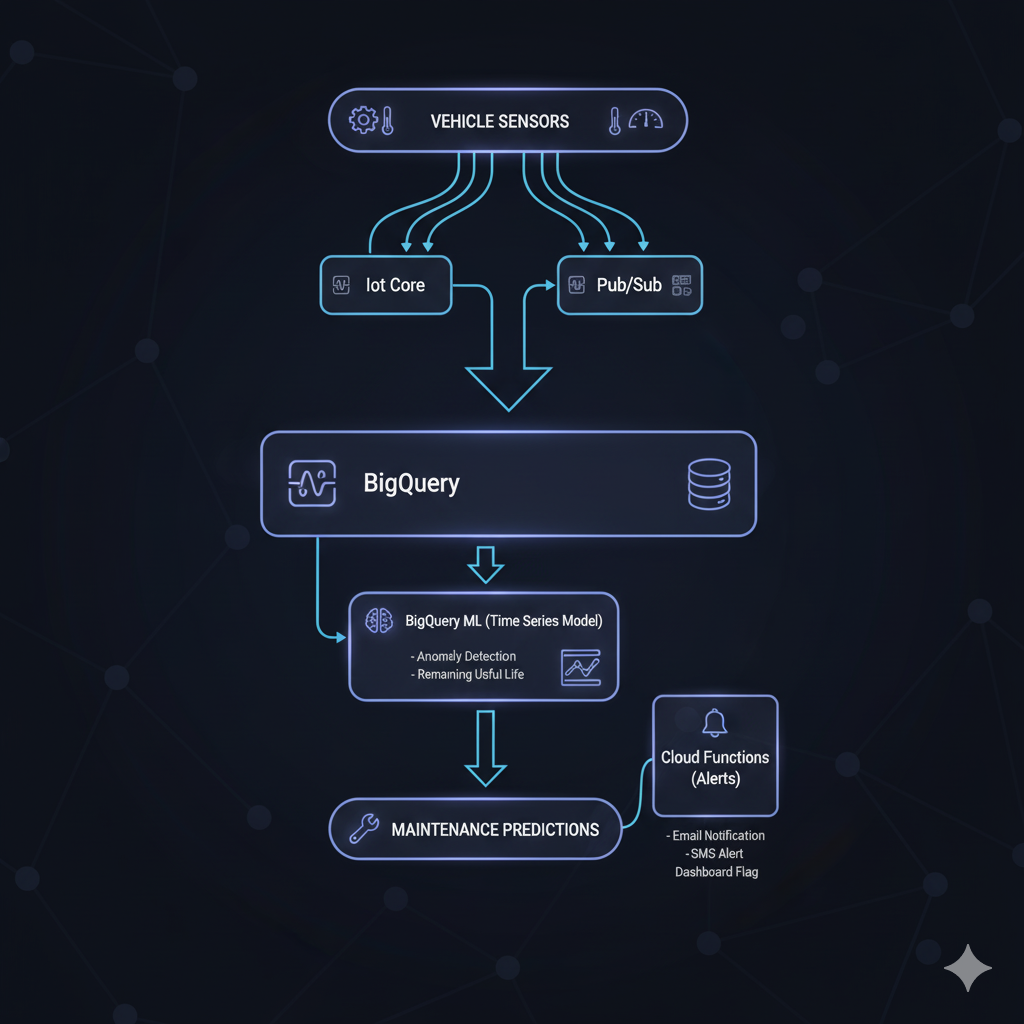
Implementation Details:
Data Collection:
Engine diagnostics (OBD-II): RPM, temperature, pressure
Telematics: Mileage, idle time, harsh events
Historical maintenance records
Environmental factors: Weather, road conditions
BigQuery ML Implementation (No-Code Approach):
-- Create time series model for predicting maintenance needs
CREATE OR REPLACE MODEL `fleet_ai.predictive_maintenance_model`
OPTIONS(
model_type='ARIMA_PLUS',
time_series_timestamp_col='timestamp',
time_series_data_col='engine_health_score',
time_series_id_col='vehicle_id',
horizon=7, -- Predict 7 days ahead
auto_arima=TRUE,
data_frequency='AUTO_FREQUENCY'
) AS
SELECT
vehicle_id,
timestamp,
-- Composite health score
(100 - (
(engine_temp_deviation * 0.3) +
(oil_pressure_deviation * 0.25) +
(brake_wear_percentage * 0.2) +
(battery_health_score * 0.15) +
(tire_pressure_deviation * 0.1)
)) AS engine_health_score
FROM `fleet_ai.vehicle_telemetry`
WHERE timestamp >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY);
-- Generate predictions
SELECT
vehicle_id,
forecast_timestamp,
forecast_value AS predicted_health_score,
standard_error,
confidence_level,
-- Alert if predicted health drops below 70
CASE
WHEN forecast_value < 70 THEN 'CRITICAL - Schedule Maintenance'
WHEN forecast_value < 80 THEN 'WARNING - Monitor Closely'
ELSE 'HEALTHY'
END AS maintenance_status
FROM ML.FORECAST(
MODEL `fleet_ai.predictive_maintenance_model`,
STRUCT(7 AS horizon, 0.95 AS confidence_level)
)
WHERE forecast_value < 85
ORDER BY vehicle_id, forecast_timestamp;
Advanced: Vertex AI Custom Model (for complex patterns):
For fleets with complex failure modes, use Vertex AI:
from google.cloud import aiplatform
from google.cloud.aiplatform import gapic as aip
# Initialize Vertex AI
aiplatform.init(project='your-project-id', location='us-central1')
# Create and train AutoML forecasting model
dataset = aiplatform.TimeSeriesDataset.create(
display_name='fleet_maintenance_forecast',
gcs_source='gs://fleet-data/maintenance_history.csv',
bq_source='bq://fleet_ai.maintenance_history'
)
training_job = aiplatform.AutoMLForecastingTrainingJob(
display_name='predictive_maintenance_v1',
optimization_objective='minimize-rmse',
column_specs={
'timestamp': 'timestamp',
'vehicle_id': 'time_series_identifier',
'component_health': 'target',
}
)
model = training_job.run(
dataset=dataset,
target_column='component_health',
time_column='timestamp',
time_series_identifier_column='vehicle_id',
forecast_horizon=7,
budget_milli_node_hours=1000
)
Outcome:
35-40% reduction in unplanned downtime
$150-200 saved per vehicle monthly
Maintenance scheduling optimization
2. Route Optimization - Agentic AI with Gemini
Problem: Drivers waste 20-30% of time in non-optimal routes due to traffic, weather, and poor planning.
GCP Solution Architecture:
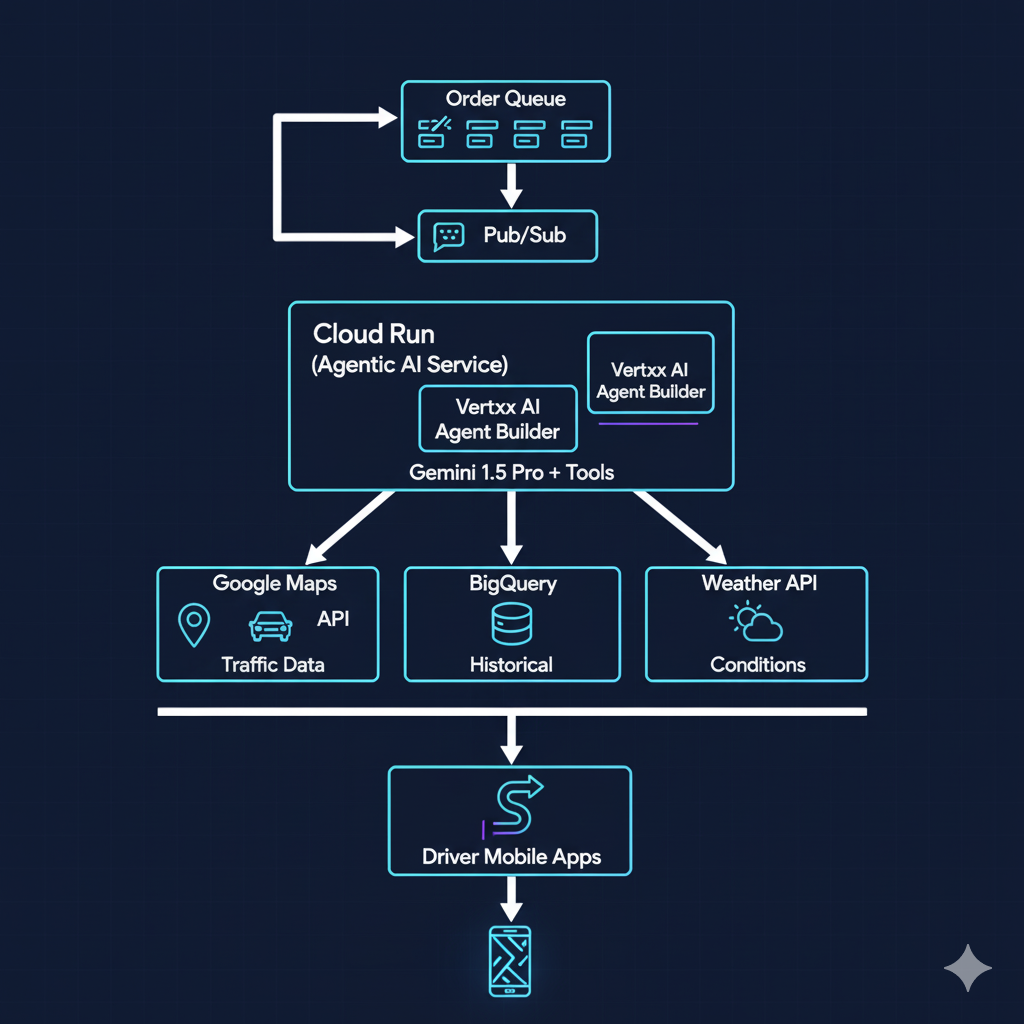
Implementation: Agentic AI Dispatcher
from google.cloud import aiplatform
from vertexai.preview import reasoning_engines
import googlemaps
from datetime import datetime
# Initialize Gemini Agent with Tools
class FleetRoutingAgent:
def __init__(self):
self.gmaps = googlemaps.Client(key='YOUR_MAPS_API_KEY')
self.model = "gemini-1.5-pro-002"
def get_traffic_conditions(self, origin, destination):
"""Tool: Get real-time traffic data"""
directions = self.gmaps.directions(
origin, destination,
mode="driving",
departure_time=datetime.now(),
traffic_model="best_guess"
)
return {
'duration_in_traffic': directions[0]['legs'][0]['duration_in_traffic'],
'distance': directions[0]['legs'][0]['distance'],
'traffic_severity': self._calculate_traffic_severity(directions)
}
def get_weather_forecast(self, location):
"""Tool: Get weather conditions affecting driving"""
# Call Weather API
pass
def get_historical_route_performance(self, route_id):
"""Tool: Query BigQuery for historical route data"""
from google.cloud import bigquery
query = f"""
SELECT
route_id,
AVG(actual_duration) as avg_duration,
AVG(fuel_consumed) as avg_fuel,
COUNT(*) as trip_count,
AVG(driver_rating) as avg_rating
FROM `fleet_ai.completed_trips`
WHERE route_id = '{route_id}'
GROUP BY route_id
"""
client = bigquery.Client()
return list(client.query(query).result())
def optimize_routes(self, delivery_orders, available_vehicles):
"""Main agentic workflow"""
# Define the agent with tools
agent_prompt = """
You are an expert fleet route optimization agent. Your goal is to:
1. Minimize total travel time and fuel consumption
2. Balance load across available vehicles
3. Account for real-time traffic and weather
4. Meet all delivery time windows
5. Optimize driver workload (max 8 hours)
Available Tools:
- get_traffic_conditions(origin, destination)
- get_weather_forecast(location)
- get_historical_route_performance(route_id)
For each set of delivery orders:
1. Analyze delivery locations and time windows
2. Check current traffic conditions for potential routes
3. Review historical performance data
4. Consider weather impact
5. Generate optimized route assignments
Return a JSON structure with:
- vehicle assignments
- optimized stop sequence
- estimated times
- fuel estimates
- risk factors
"""
# Create agent instance
agent = reasoning_engines.LangchainAgent(
model=self.model,
tools=[
self.get_traffic_conditions,
self.get_weather_forecast,
self.get_historical_route_performance
],
agent_executor_kwargs={
"system_message": agent_prompt
}
)
# Execute optimization
optimization_request = f"""
Optimize routes for the following:
Delivery Orders: {delivery_orders}
Available Vehicles: {available_vehicles}
Current Time: {datetime.now().isoformat()}
Provide optimized routing plan.
"""
result = agent.query(optimization_request)
return result
# Usage
agent = FleetRoutingAgent()
orders = [
{'order_id': 'ORD001', 'address': '123 Main St', 'time_window': '10:00-12:00'},
{'order_id': 'ORD002', 'address': '456 Oak Ave', 'time_window': '11:00-13:00'},
# ... more orders
]
vehicles = [
{'vehicle_id': 'VEH001', 'current_location': 'Depot A', 'capacity': 1000},
{'vehicle_id': 'VEH002', 'current_location': 'Depot A', 'capacity': 1500},
]
optimized_plan = agent.optimize_routes(orders, vehicles)
Outcome:
15-25% reduction in total route time
18-22% fuel savings
95%+ on-time delivery rate
3. Driver Behavior Monitoring - Classification with BigQuery ML
Problem: Risky driving causes 85% of fleet accidents and increases insurance costs.
GCP Solution Architecture:
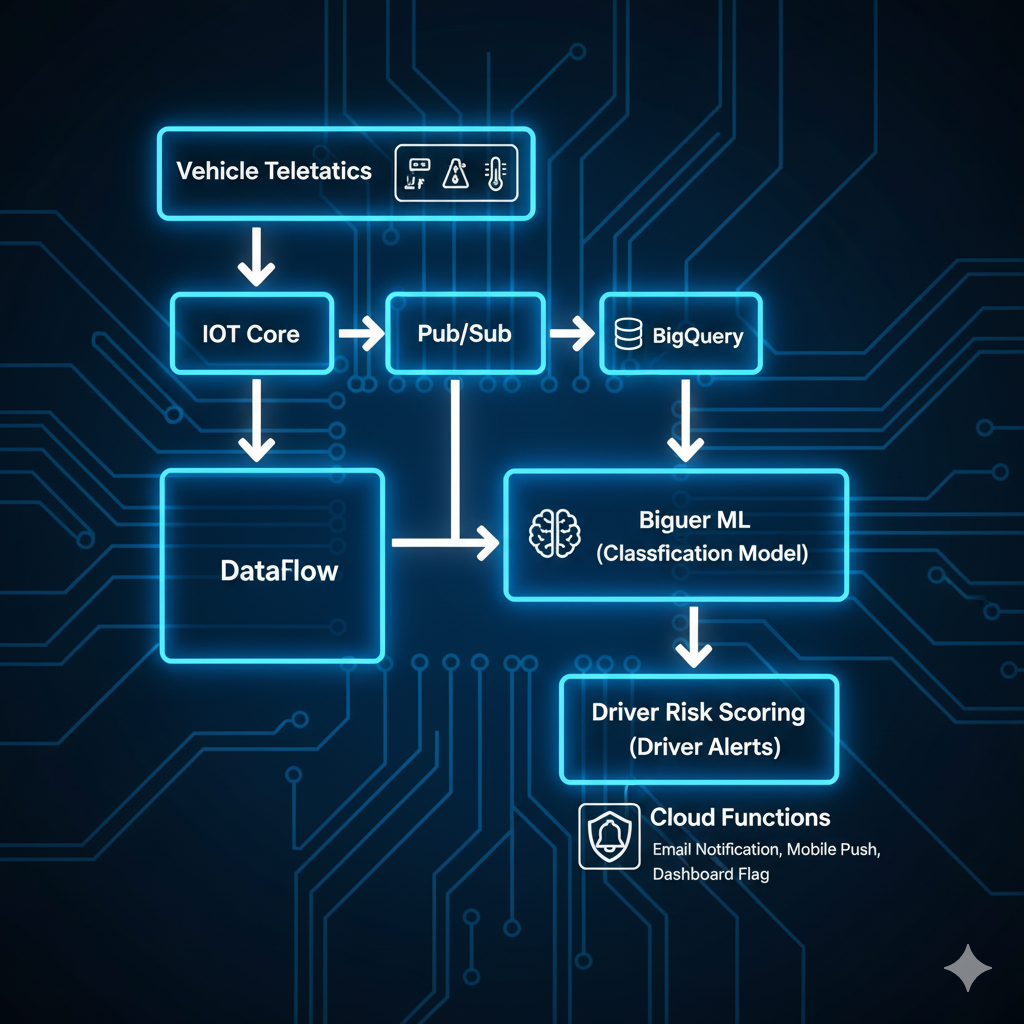
Implementation:
-- Step 1: Create labeled training dataset
CREATE OR REPLACE TABLE `fleet_ai.driver_behavior_training` AS
SELECT
driver_id,
trip_id,
-- Behavior metrics (last 30 days)
AVG(speed_violations) as avg_speed_violations,
AVG(harsh_braking_events) as avg_harsh_braking,
AVG(harsh_acceleration) as avg_harsh_acceleration,
AVG(harsh_cornering) as avg_harsh_cornering,
AVG(phone_usage_minutes) as avg_distraction_time,
SUM(seatbelt_violations) as total_seatbelt_violations,
AVG(following_distance_violations) as avg_tailgating,
-- Trip characteristics
AVG(night_driving_hours) as avg_night_hours,
AVG(highway_miles_percentage) as highway_percentage,
AVG(idle_time_minutes) as avg_idle_time,
-- Historical data
COUNT(DISTINCT accident_involved) as accident_count,
AVG(customer_rating) as avg_customer_rating,
-- Target variable (SAFE, MODERATE, HIGH_RISK)
CASE
WHEN accident_count >= 2
OR AVG(speed_violations) > 5
OR AVG(harsh_braking_events) > 8 THEN 'HIGH_RISK'
WHEN AVG(speed_violations) > 2
OR AVG(harsh_braking_events) > 4 THEN 'MODERATE_RISK'
ELSE 'SAFE'
END as risk_category
FROM `fleet_ai.telematics_raw`
GROUP BY driver_id, trip_id;
-- Step 2: Create multiclass classification model
CREATE OR REPLACE MODEL `fleet_ai.driver_risk_classifier`
OPTIONS(
model_type='LOGISTIC_REG',
auto_class_weights=TRUE,
input_label_cols=['risk_category'],
max_iterations=50,
l1_reg=0.1,
data_split_method='AUTO_SPLIT'
) AS
SELECT
* EXCEPT(driver_id, trip_id)
FROM `fleet_ai.driver_behavior_training`;
-- Step 3: Evaluate model performance
SELECT
roc_auc,
precision,
recall,
accuracy,
f1_score
FROM ML.EVALUATE(
MODEL `fleet_ai.driver_risk_classifier`,
(SELECT * FROM `fleet_ai.driver_behavior_training`)
);
-- Step 4: Real-time driver scoring
CREATE OR REPLACE TABLE `fleet_ai.driver_risk_scores` AS
SELECT
driver_id,
predicted_risk_category,
predicted_risk_category_probs,
-- Extract probability scores
prob.prob as risk_probability,
prob.label as risk_level
FROM ML.PREDICT(
MODEL `fleet_ai.driver_risk_classifier`,
(
SELECT * FROM `fleet_ai.current_driver_metrics`
)
),
UNNEST(predicted_risk_category_probs) as prob
WHERE prob.label = predicted_risk_category;
-- Step 5: Generate alerts for high-risk drivers
CREATE OR REPLACE TABLE `fleet_ai.driver_alerts` AS
SELECT
driver_id,
predicted_risk_category,
risk_probability,
CASE
WHEN predicted_risk_category = 'HIGH_RISK'
AND risk_probability > 0.75 THEN 'IMMEDIATE_INTERVENTION'
WHEN predicted_risk_category = 'HIGH_RISK' THEN 'SCHEDULE_TRAINING'
WHEN predicted_risk_category = 'MODERATE_RISK' THEN 'MONITOR_CLOSELY'
ELSE 'NO_ACTION'
END as recommended_action,
-- Identify specific behaviors to coach
CASE
WHEN avg_speed_violations > 5 THEN 'Speed Management Training'
WHEN avg_harsh_braking > 8 THEN 'Defensive Driving Course'
WHEN avg_distraction_time > 30 THEN 'Distraction Awareness Training'
END as training_recommendation
FROM `fleet_ai.driver_risk_scores`
JOIN `fleet_ai.current_driver_metrics` USING(driver_id)
WHERE predicted_risk_category IN ('HIGH_RISK', 'MODERATE_RISK');
Dashboard Integration (Cloud Run API):
from flask import Flask, jsonify
from google.cloud import bigquery
import json
app = Flask(__name__)
client = bigquery.Client()
@app.route('/api/driver-risk/<driver_id>', methods=['GET'])
def get_driver_risk(driver_id):
query = f"""
SELECT
driver_id,
predicted_risk_category,
risk_probability,
recommended_action,
training_recommendation,
avg_speed_violations,
avg_harsh_braking,
avg_harsh_acceleration
FROM `fleet_ai.driver_alerts`
WHERE driver_id = '{driver_id}'
"""
results = client.query(query).result()
driver_data = [dict(row) for row in results]
return jsonify(driver_data)
@app.route('/api/fleet-risk-summary', methods=['GET'])
def get_fleet_summary():
query = """
SELECT
predicted_risk_category,
COUNT(*) as driver_count,
AVG(risk_probability) as avg_risk_score
FROM `fleet_ai.driver_risk_scores`
GROUP BY predicted_risk_category
"""
results = client.query(query).result()
summary = [dict(row) for row in results]
return jsonify(summary)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)
Outcome:
40-50% reduction in accidents
25-30% lower insurance premiums
Improved driver retention through coaching
4. Fuel Consumption Optimization - Regression & Anomaly Detection
Problem: Fuel typically represents 30-40% of total fleet operating costs.
GCP Solution Architecture:

Implementation:
-- Fuel efficiency prediction model
CREATE OR REPLACE MODEL `fleet_ai.fuel_efficiency_model`
OPTIONS(
model_type='BOOSTED_TREE_REGRESSOR',
input_label_cols=['fuel_consumed_gallons'],
max_iterations=100,
learn_rate=0.1
) AS
SELECT
vehicle_id,
driver_id,
distance_miles,
avg_speed_mph,
idle_time_minutes,
ac_usage_minutes,
load_weight_lbs,
route_type, -- highway, urban, mixed
weather_condition,
traffic_density,
elevation_change_feet,
avg_acceleration_rate,
avg_braking_rate,
fuel_consumed_gallons -- Target variable
FROM `fleet_ai.trip_data`
WHERE fuel_consumed_gallons IS NOT NULL;
-- Identify inefficient driving patterns
SELECT
driver_id,
vehicle_id,
predicted_fuel_consumed_gallons,
fuel_consumed_gallons as actual_fuel,
(fuel_consumed_gallons - predicted_fuel_consumed_gallons) as inefficiency_gallons,
((fuel_consumed_gallons - predicted_fuel_consumed_gallons) * 3.50) as cost_impact_usd
FROM ML.PREDICT(
MODEL `fleet_ai.fuel_efficiency_model`,
(SELECT * FROM `fleet_ai.recent_trips`)
)
WHERE ABS(fuel_consumed_gallons - predicted_fuel_consumed_gallons) > 2
ORDER BY inefficiency_gallons DESC;
-- Anomaly detection for fuel theft
CREATE OR REPLACE MODEL `fleet_ai.fuel_anomaly_detector`
OPTIONS(
model_type='AUTOML_REGRESSOR',
input_label_cols=['fuel_level_change']
) AS
SELECT
vehicle_id,
timestamp,
fuel_level_before,
fuel_level_after,
(fuel_level_before - fuel_level_after) as fuel_level_change,
engine_running,
gps_location_lat,
gps_location_lng,
distance_traveled_miles
FROM `fleet_ai.fuel_events`
WHERE distance_traveled_miles > 0;
-- Detect suspicious fuel events
SELECT
vehicle_id,
timestamp,
fuel_level_change,
predicted_fuel_level_change,
ABS(fuel_level_change - predicted_fuel_level_change) as anomaly_score,
CASE
WHEN ABS(fuel_level_change - predicted_fuel_level_change) > 5
AND engine_running = FALSE THEN 'POTENTIAL_THEFT'
WHEN ABS(fuel_level_change - predicted_fuel_level_change) > 10 THEN 'SENSOR_MALFUNCTION'
ELSE 'NORMAL'
END as alert_type
FROM ML.PREDICT(
MODEL `fleet_ai.fuel_anomaly_detector`,
(SELECT * FROM `fleet_ai.fuel_events_realtime`)
)
WHERE ABS(fuel_level_change - predicted_fuel_level_change) > 3;
Outcome:
12-18% fuel cost reduction
Detection of fuel theft (2-5% of fuel budget)
Data-driven driver coaching
5. Demand Forecasting - Time Series with Vertex AI
Problem: Poor demand prediction leads to over/under-utilization of fleet resources.
GCP Solution Architecture:
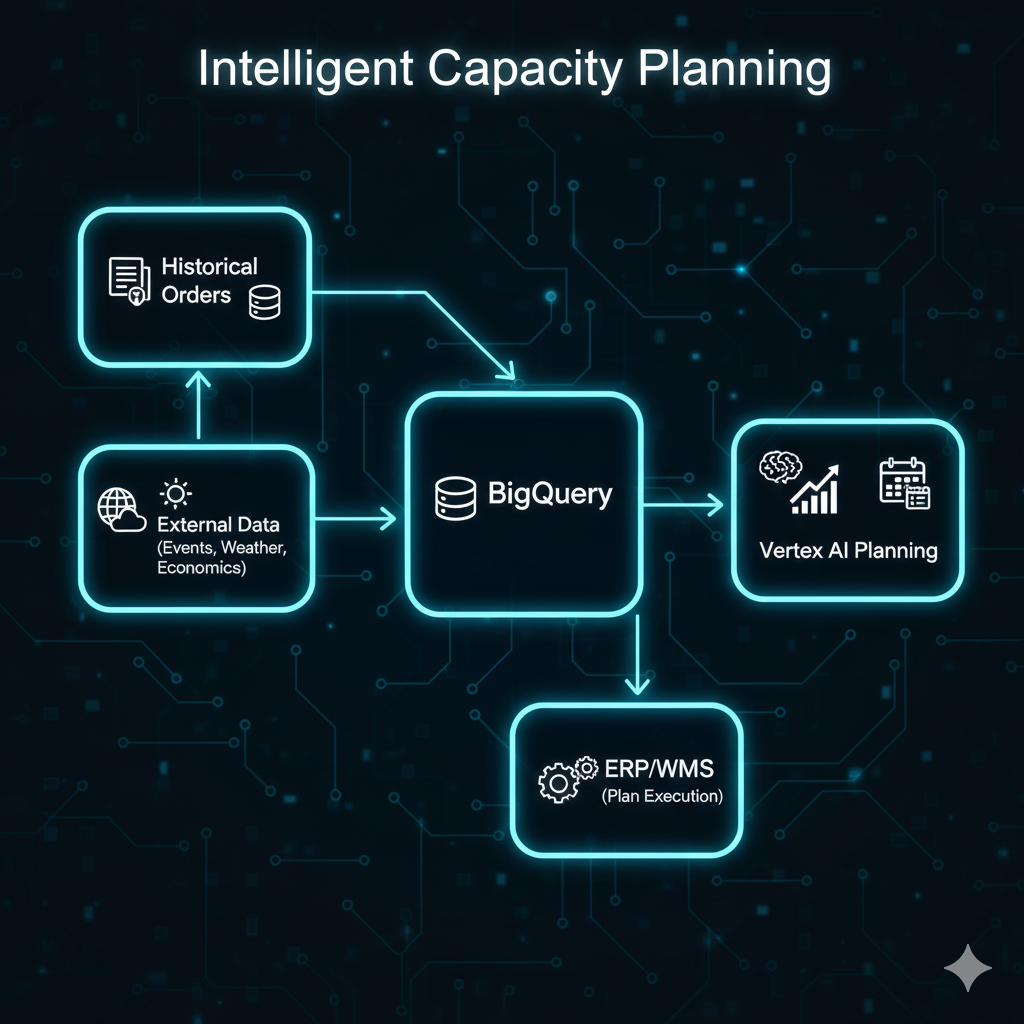
Implementation:
from google.cloud import aiplatform
from google.cloud.aiplatform import gapic as aip
# Initialize Vertex AI
aiplatform.init(project='your-project-id', location='us-central1')
# Prepare forecasting dataset
dataset = aiplatform.TimeSeriesDataset.create(
display_name='fleet_demand_forecast',
gcs_source='gs://fleet-data/demand_history.csv',
)
# Create AutoML forecasting training job
training_job = aiplatform.AutoMLForecastingTrainingJob(
display_name='demand_forecast_v1',
optimization_objective='minimize-quantile-loss',
)
# Train model with external regressors
model = training_job.run(
dataset=dataset,
target_column='order_volume',
time_column='date',
time_series_identifier_column='service_area',
forecast_horizon=14, # 2 weeks ahead
context_window=90, # Use 90 days of history
budget_milli_node_hours=1000,
# Additional features
column_transformations=[
{'categorical': 'day_of_week'},
{'categorical': 'is_holiday'},
{'numeric': 'weather_temperature'},
{'numeric': 'local_event_indicator'},
]
)
# Deploy model for online predictions
endpoint = model.deploy(
machine_type='n1-standard-4',
min_replica_count=1,
max_replica_count=3
)
# Make predictions
predictions = endpoint.predict(
instances=[{
'service_area': 'ZONE_A',
'forecast_horizon': 14,
'confidence_level': 0.95
}]
)
print(f"Forecasted demand: {predictions.predictions}")
BigQuery Integration:
-- Store predictions
CREATE OR REPLACE TABLE `fleet_ai.demand_forecasts` AS
SELECT
service_area,
forecast_date,
predicted_order_volume,
confidence_interval_lower,
confidence_interval_upper,
-- Recommended fleet size
CAST(CEIL(predicted_order_volume / 25) AS INT64) as recommended_vehicles,
-- Cost optimization
CASE
WHEN predicted_order_volume < (SELECT AVG(order_volume) * 0.7 FROM historical_orders)
THEN 'REDUCE_FLEET'
WHEN predicted_order_volume > (SELECT AVG(order_volume) * 1.3 FROM historical_orders)
THEN 'EXPAND_FLEET'
ELSE 'MAINTAIN_FLEET'
END as fleet_action
FROM `fleet_ai.vertex_predictions`;
Outcome:
20-25% improvement in fleet utilization
Reduced overtime costs
Better customer service (shorter wait times)
6. Automated Dispatching - Agentic AI with Real-Time Optimization
Problem: Manual dispatching is slow, error-prone, and fails to account for dynamic conditions.
GCP Solution Architecture:
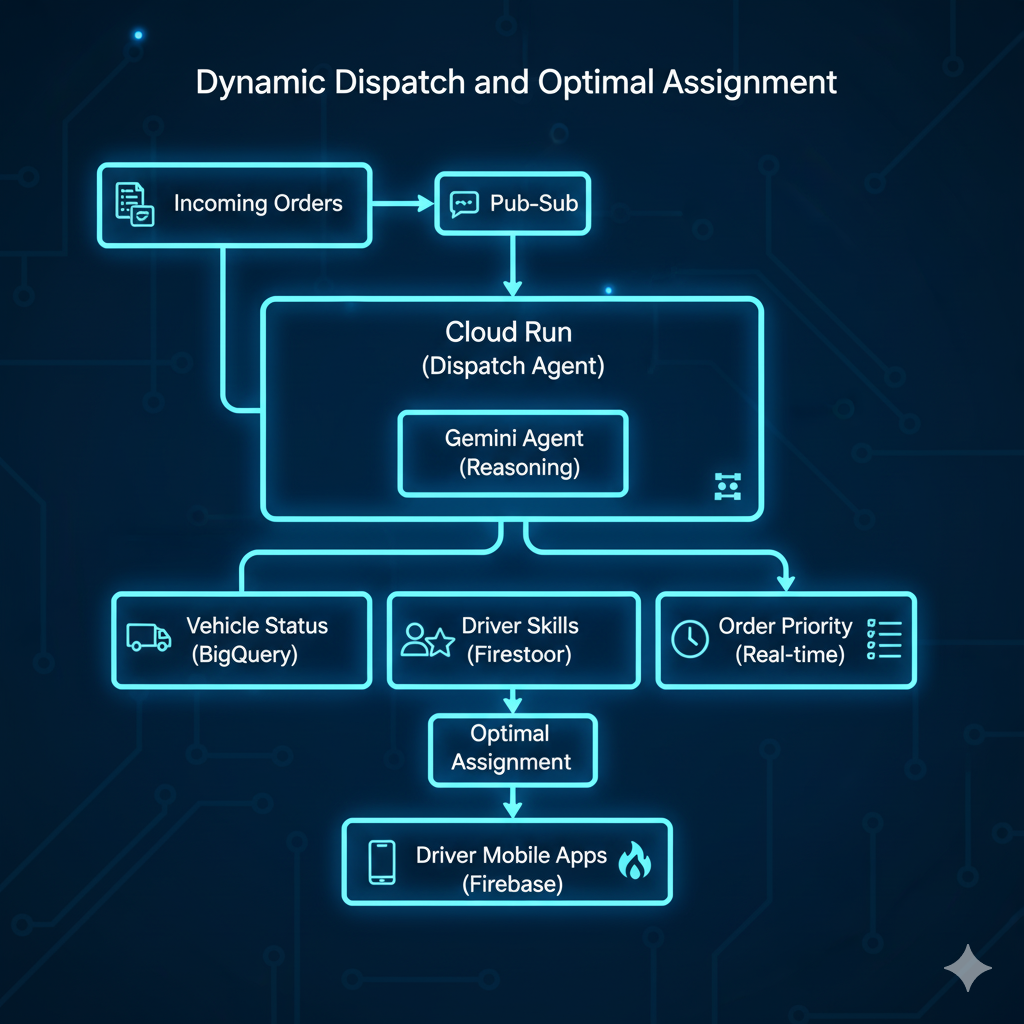
Implementation:
from vertexai.preview.generative_models import GenerativeModel
import json
class FleetDispatchAgent:
def __init__(self):
self.model = GenerativeModel("gemini-1.5-pro-002")
def get_available_vehicles(self):
"""Get real-time vehicle availability from BigQuery"""
query = """
SELECT
vehicle_id,
driver_id,
current_location_lat,
current_location_lng,
current_capacity_available,
estimated_completion_time,
driver_hours_remaining,
vehicle_type,
special_equipment
FROM `fleet_ai.vehicle_status_realtime`
WHERE status = 'AVAILABLE' OR estimated_completion_time < TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 30 MINUTE)
"""
# Execute query and return results
pass
def get_driver_skills(self, driver_id):
"""Get driver qualifications from Firestore"""
# Hazmat certified, temperature controlled, oversized loads, etc.
pass
def calculate_eta(self, vehicle_location, delivery_location):
"""Calculate ETA using Google Maps Distance Matrix API"""
pass
def dispatch_order(self, order):
"""Main dispatch logic with agentic reasoning"""
# Get context
available_vehicles = self.get_available_vehicles()
# Create dispatch prompt for Gemini
dispatch_prompt = f"""
You are an expert fleet dispatcher. Assign the following order to the best vehicle.
ORDER DETAILS:
{json.dumps(order, indent=2)}
AVAILABLE VEHICLES:
{json.dumps(available_vehicles, indent=2)}
DISPATCH RULES:
1. Minimize customer wait time (ETA)
2. Maximize vehicle utilization
3. Respect driver hours-of-service regulations
4. Match special requirements (equipment, certifications)
5. Consider order priority and SLA
6. Balance workload across drivers
ANALYZE:
1. Which vehicles can fulfill this order's requirements?
2. What is the ETA for each candidate vehicle?
3. What is the impact on each driver's remaining capacity?
4. Are there any upcoming orders that would benefit from batching?
5. What is the optimal assignment?
RESPOND IN JSON:
{{
"assigned_vehicle_id": "string",
"assigned_driver_id": "string",
"estimated_pickup_time": "ISO timestamp",
"estimated_delivery_time": "ISO timestamp",
"reasoning": "Brief explanation of assignment logic",
"alternative_options": ["array of other viable options"],
"risk_factors": ["potential issues to monitor"]
}}
"""
# Get Gemini's recommendation
response = self.model.generate_content(dispatch_prompt)
dispatch_decision = json.loads(response.text)
# Validate and execute assignment
self.assign_order_to_vehicle(
order_id=order['order_id'],
vehicle_id=dispatch_decision['assigned_vehicle_id'],
driver_id=dispatch_decision['assigned_driver_id']
)
# Send notification to driver
self.notify_driver(
driver_id=dispatch_decision['assigned_driver_id'],
order_details=order,
eta=dispatch_decision['estimated_pickup_time']
)
return dispatch_decision
# Usage
agent = FleetDispatchAgent()
new_order = {
'order_id': 'ORD-12345',
'pickup_location': {'lat': 37.7749, 'lng': -122.4194},
'delivery_location': {'lat': 37.8044, 'lng': -122.2712},
'priority': 'HIGH',
'time_window': '14:00-16:00',
'weight': 500, # lbs
'special_requirements': ['temperature_controlled', 'fragile']
}
dispatch_result = agent.dispatch_order(new_order)
Real-Time Optimization with Pub/Sub:
from google.cloud import pubsub_v1
import json
# Subscribe to order events
subscriber = pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path('project-id', 'order-events')
def callback(message):
order_data = json.loads(message.data)
# Process new order through dispatch agent
agent = FleetDispatchAgent()
result = agent.dispatch_order(order_data)
# Acknowledge message
message.ack()
print(f"Dispatched order {order_data['order_id']} to vehicle {result['assigned_vehicle_id']}")
# Listen for orders
streaming_pull_future = subscriber.subscribe(subscription_path, callback=callback)
print("Listening for order events...")
try:
streaming_pull_future.result()
except KeyboardInterrupt:
streaming_pull_future.cancel()
Outcome:
60-70% faster dispatch times (30 seconds vs 5-10 minutes)
15-20% improvement in first-trip-of-day ETAs
90%+ driver satisfaction with assignments
7. Real-Time Fleet Monitoring - Vision AI & Anomaly Detection
Problem: Monitoring hundreds of vehicles manually is impossible; critical events get missed.
GCP Solution Architecture:
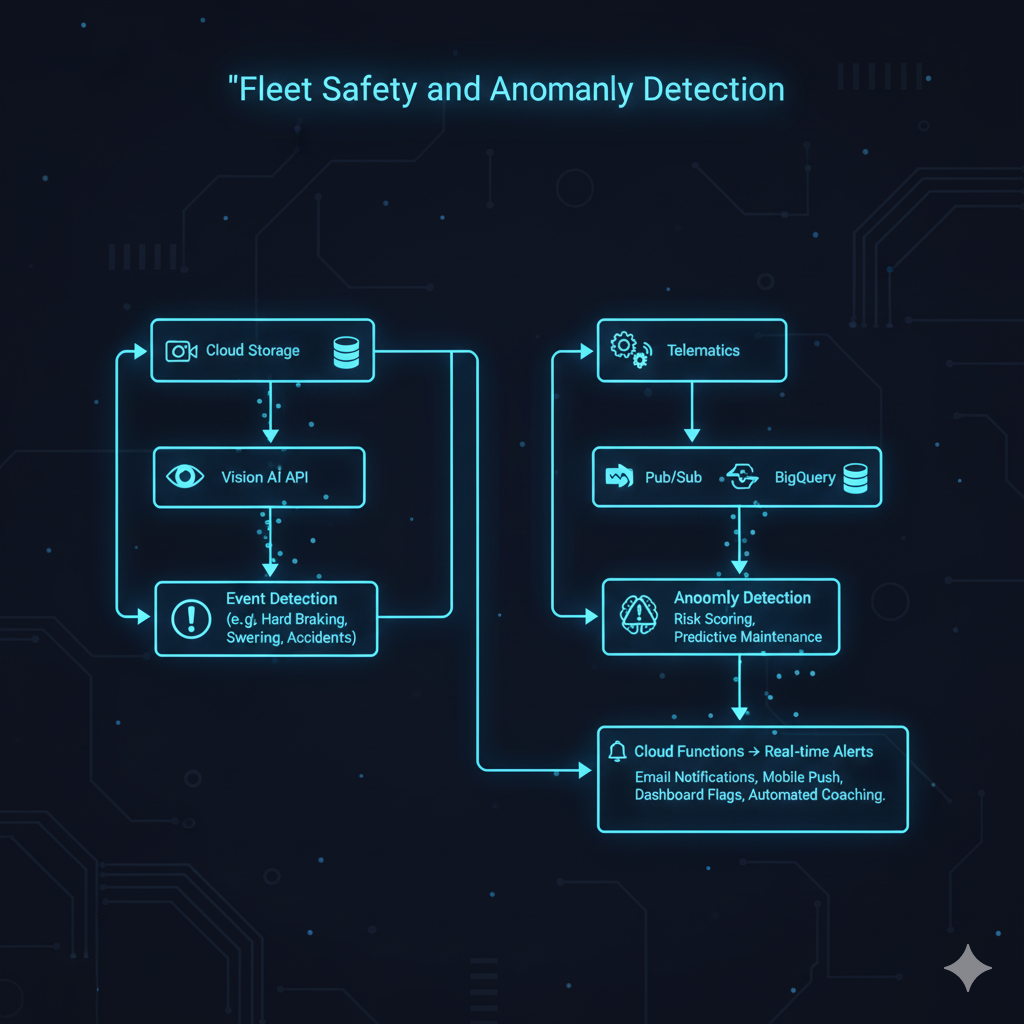
Implementation:
from google.cloud import vision
from google.cloud import storage
import json
class FleetMonitoringSystem:
def __init__(self):
self.vision_client = vision.ImageAnnotatorClient()
self.storage_client = storage.Client()
def analyze_dashcam_frame(self, gcs_uri):
"""Analyze dashcam image for safety events"""
image = vision.Image()
image.source.image_uri = gcs_uri
# Detect objects (vehicles, pedestrians, cyclists)
objects = self.vision_client.object_localization(image=image).localized_object_annotations
# Detect faces (driver distraction, drowsiness)
faces = self.vision_client.face_detection(image=image).face_annotations
# Detect text (traffic signs, license plates)
texts = self.vision_client.text_detection(image=image).text_annotations
# Analyze for safety events
events = []
for obj in objects:
if obj.name == 'Person' and obj.score > 0.7:
events.append({
'type': 'PEDESTRIAN_DETECTED',
'confidence': obj.score,
'location': obj.bounding_poly
})
for face in faces:
# Check for driver distraction indicators
if face.detection_confidence > 0.8:
# Analyze gaze direction
if face.pan_angle > 45 or face.pan_angle < -45:
events.append({
'type': 'DRIVER_DISTRACTION',
'severity': 'HIGH',
'details': 'Driver looking away from road'
})
# Check for drowsiness (eyes closed)
if face.joy_likelihood < vision.Likelihood.POSSIBLE:
events.append({
'type': 'DRIVER_DROWSINESS',
'severity': 'CRITICAL',
'details': 'Possible drowsiness detected'
})
return events
def monitor_vehicle_telemetry(self, telemetry_data):
"""Real-time anomaly detection on telemetry data"""
anomalies = []
# Temperature anomalies
if telemetry_data.get('engine_temp') > 220: # °F
anomalies.append({
'type': 'ENGINE_OVERHEAT',
'severity': 'CRITICAL',
'value': telemetry_data['engine_temp']
})
# Sudden acceleration/braking
if abs(telemetry_data.get('acceleration', 0)) > 0.4: # g-force
anomalies.append({
'type': 'HARSH_EVENT',
'severity': 'MEDIUM',
'details': 'Sudden acceleration or braking detected'
})
# Geofence violations
if not self.is_in_authorized_zone(telemetry_data['location']):
anomalies.append({
'type': 'GEOFENCE_VIOLATION',
'severity': 'HIGH',
'location': telemetry_data['location']
})
return anomalies
# Cloud Function for real-time processing
def process_telemetry_event(event, context):
"""Triggered by Pub/Sub messages"""
import base64
telemetry = json.loads(base64.b64decode(event['data']))
monitor = FleetMonitoringSystem()
anomalies = monitor.monitor_vehicle_telemetry(telemetry)
# Send alerts if critical anomalies detected
if any(a['severity'] == 'CRITICAL' for a in anomalies):
send_alert_to_dispatcher(telemetry['vehicle_id'], anomalies)
# Log to BigQuery for analysis
log_to_bigquery(telemetry, anomalies)
BigQuery Streaming Anomaly Detection:
-- Real-time anomaly detection using statistical methods
CREATE OR REPLACE TABLE `fleet_ai.telemetry_anomalies` AS
WITH telemetry_stats AS (
SELECT
vehicle_id,
AVG(engine_temp) as avg_temp,
STDDEV(engine_temp) as stddev_temp,
AVG(speed_mph) as avg_speed,
STDDEV(speed_mph) as stddev_speed
FROM `fleet_ai.telemetry_stream`
WHERE timestamp >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR)
GROUP BY vehicle_id
),
current_readings AS (
SELECT
vehicle_id,
timestamp,
engine_temp,
speed_mph,
oil_pressure,
battery_voltage
FROM `fleet_ai.telemetry_stream`
WHERE timestamp >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 5 MINUTE)
)
SELECT
c.vehicle_id,
c.timestamp,
c.engine_temp,
s.avg_temp,
-- Z-score for temperature
(c.engine_temp - s.avg_temp) / NULLIF(s.stddev_temp, 0) as temp_z_score,
-- Anomaly flags
CASE
WHEN ABS((c.engine_temp - s.avg_temp) / NULLIF(s.stddev_temp, 0)) > 3 THEN TRUE
ELSE FALSE
END as is_temp_anomaly,
CASE
WHEN ABS((c.speed_mph - s.avg_speed) / NULLIF(s.stddev_speed, 0)) > 3 THEN TRUE
ELSE FALSE
END as is_speed_anomaly,
CASE
WHEN c.oil_pressure < 20 OR c.oil_pressure > 80 THEN TRUE
ELSE FALSE
END as is_pressure_anomaly
FROM current_readings c
JOIN telemetry_stats s USING(vehicle_id)
WHERE
ABS((c.engine_temp - s.avg_temp) / NULLIF(s.stddev_temp, 0)) > 2
OR ABS((c.speed_mph - s.avg_speed) / NULLIF(s.stddev_speed, 0)) > 2
OR c.oil_pressure < 20
OR c.oil_pressure > 80;
Outcome:
Real-time detection of critical safety events
50% reduction in response time to incidents
Improved driver safety through proactive interventions
8. Accident Prevention - Computer Vision + Real-Time Alerts
Problem: Most accidents are preventable with early warning systems.
GCP Solution Architecture:
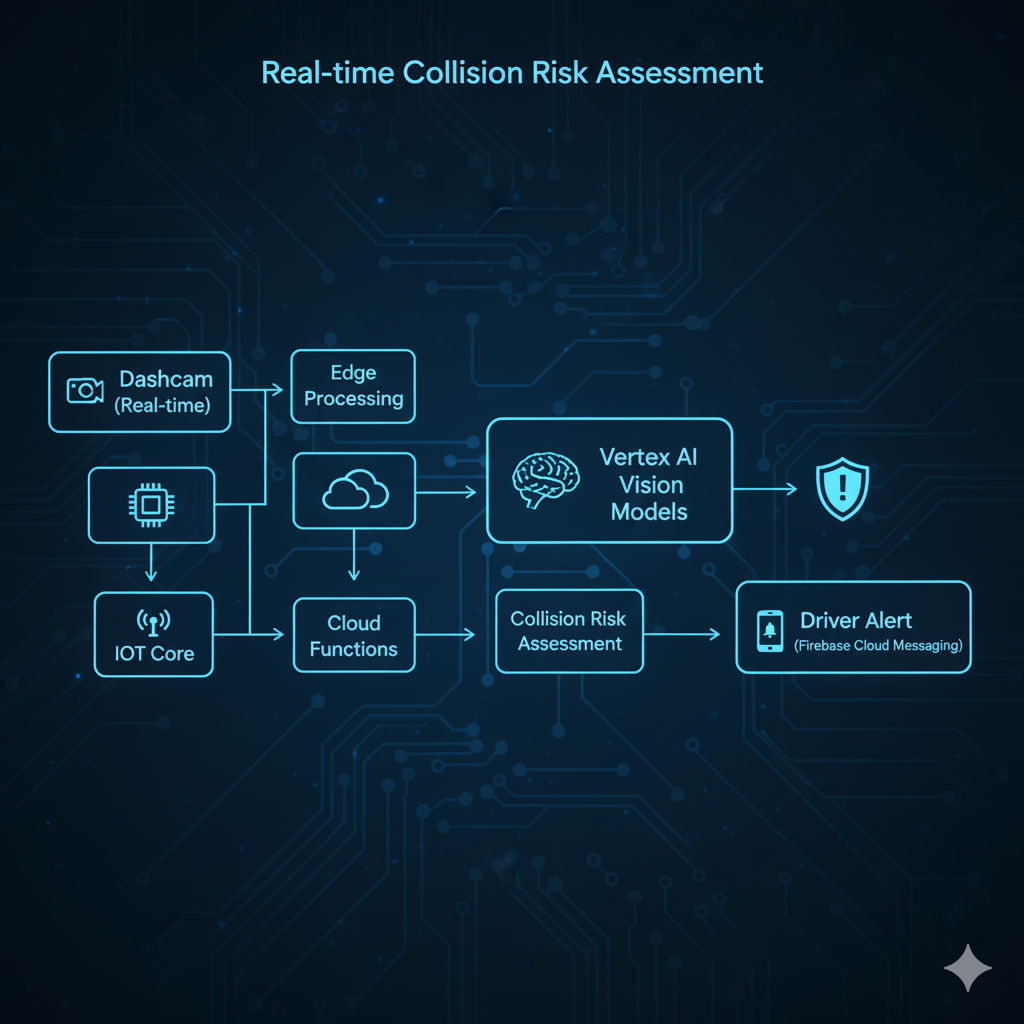
Implementation:
from google.cloud import aiplatform
from vertexai.vision_models import MultiModalEmbeddingModel, Image
import numpy as np
class CollisionPreventionSystem:
def __init__(self):
self.embedding_model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding@001")
def analyze_collision_risk(self, current_frame, vehicle_speed, following_distance):
"""Analyze collision risk using vision embeddings and telemetry"""
# Load current dashcam frame
image = Image.load_from_file(current_frame)
# Get embeddings
embeddings = self.embedding_model.get_embeddings(
image=image,
contextual_text="dashcam view forward"
)
# Detect objects in scene
image_embedding = embeddings.image_embedding
# Calculate risk factors
risk_score = 0
risk_factors = []
# Speed-based risk
if vehicle_speed > 70: # mph
risk_score += 20
risk_factors.append("HIGH_SPEED")
# Following distance risk
if following_distance < (vehicle_speed * 0.5): # Rule: 1 car length per 10mph
risk_score += 40
risk_factors.append("FOLLOWING_TOO_CLOSE")
# Object detection risk (using pre-trained model)
detected_objects = self.detect_objects(image)
for obj in detected_objects:
if obj['type'] in ['pedestrian', 'cyclist']:
risk_score += 30
risk_factors.append(f"VULNERABLE_ROAD_USER_{obj['type']}")
if obj['type'] == 'vehicle' and obj['distance'] < 50: # feet
risk_score += 25
risk_factors.append("VEHICLE_PROXIMITY")
# Risk classification
if risk_score >= 70:
risk_level = "CRITICAL"
action = "IMMEDIATE_BRAKING_SUGGESTED"
elif risk_score >= 40:
risk_level = "HIGH"
action = "SLOW_DOWN"
elif risk_score >= 20:
risk_level = "MODERATE"
action = "INCREASE_FOLLOWING_DISTANCE"
else:
risk_level = "LOW"
action = "CONTINUE_MONITORING"
return {
'risk_score': risk_score,
'risk_level': risk_level,
'risk_factors': risk_factors,
'recommended_action': action,
'timestamp': datetime.utcnow().isoformat()
}
def send_driver_alert(self, vehicle_id, risk_assessment):
"""Send real-time alert to driver's device"""
from firebase_admin import messaging
message = messaging.Message(
notification=messaging.Notification(
title=f"⚠️ {risk_assessment['risk_level']} Risk Alert",
body=risk_assessment['recommended_action']
),
data={
'risk_score': str(risk_assessment['risk_score']),
'risk_factors': ','.join(risk_assessment['risk_factors']),
'timestamp': risk_assessment['timestamp']
},
token=self.get_driver_device_token(vehicle_id)
)
response = messaging.send(message)
return response
# Pub/Sub trigger for real-time processing
def process_dashcam_frame(event, context):
"""Process incoming dashcam frames"""
frame_data = json.loads(base64.b64decode(event['data']))
system = CollisionPreventionSystem()
risk = system.analyze_collision_risk(
current_frame=frame_data['image_uri'],
vehicle_speed=frame_data['speed_mph'],
following_distance=frame_data['following_distance_feet']
)
# Send alert if risk is high or critical
if risk['risk_level'] in ['HIGH', 'CRITICAL']:
system.send_driver_alert(frame_data['vehicle_id'], risk)
# Log event to BigQuery
log_safety_event(frame_data['vehicle_id'], risk)
Custom AutoML Vision Model for Hazard Detection:
# Train custom model for fleet-specific hazards
from google.cloud import aiplatform
# Create dataset with labeled dashcam images
dataset = aiplatform.ImageDataset.create(
display_name="fleet_hazard_detection",
gcs_source="gs://fleet-data/training_images/",
import_schema_uri=aiplatform.schema.dataset.ioformat.image.single_label_classification,
)
# Train AutoML model
job = aiplatform.AutoMLImageTrainingJob(
display_name="hazard_detector_v1",
prediction_type="classification",
model_type="CLOUD",
)
model = job.run(
dataset=dataset,
model_display_name="fleet_hazard_model",
training_fraction_split=0.8,
validation_fraction_split=0.1,
test_fraction_split=0.1,
budget_milli_node_hours=8000,
)
# Deploy for real-time predictions
endpoint = model.deploy(
machine_type="n1-standard-4",
accelerator_type="NVIDIA_TESLA_T4",
accelerator_count=1,
)
Outcome:
60-70% reduction in preventable accidents
Average 2.5 seconds of advance warning
$500K-1M annual savings in accident costs
9. Dynamic Load Planning - Optimization with Gemini
Problem: Inefficient loading wastes capacity and increases trips.
GCP Solution Architecture:
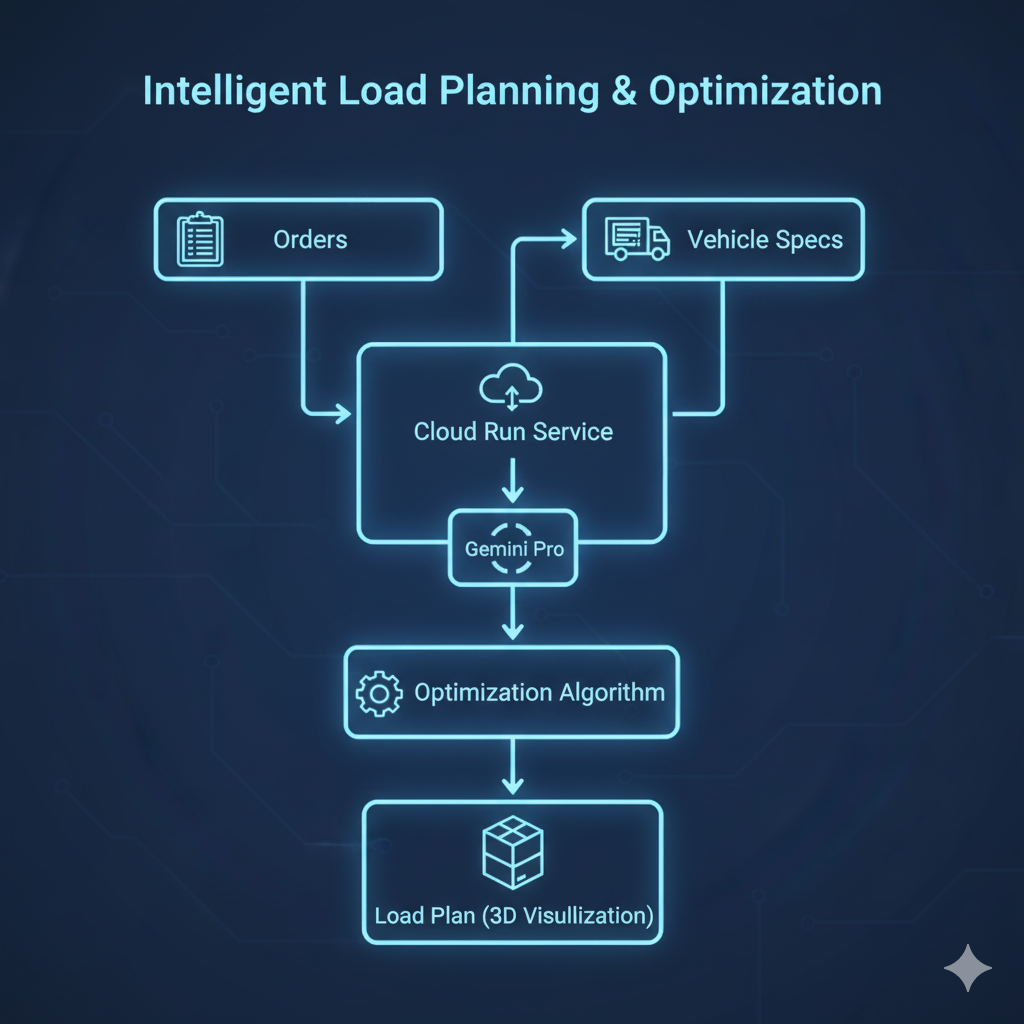
Implementation:
from vertexai.preview.generative_models import GenerativeModel
import json
class LoadPlanningOptimizer:
def __init__(self):
self.model = GenerativeModel("gemini-1.5-pro-002")
def optimize_load_plan(self, orders, vehicle_specs):
"""Generate optimal loading plan using Gemini"""
planning_prompt = f"""
You are an expert logistics optimizer. Create an optimal loading plan.
VEHICLE SPECIFICATIONS:
{json.dumps(vehicle_specs, indent=2)}
ORDERS TO LOAD:
{json.dumps(orders, indent=2)}
OPTIMIZATION CRITERIA:
1. Maximize vehicle capacity utilization
2. Ensure weight distribution balance (50/50 front/back)
3. Place heavy items on bottom, fragile on top
4. Consider delivery sequence (last in, first out)
5. Respect special handling requirements
6. Comply with DOT weight regulations
CONSTRAINTS:
- Max vehicle weight: {{vehicle_specs['max_weight_lbs']}} lbs
- Max dimensions: {{vehicle_specs['length']}} x {{vehicle_specs['width']}} x {{vehicle_specs['height']}} inches
- Axle weight limits: Front {{vehicle_specs['front_axle_limit']}} lbs, Rear {{vehicle_specs['rear_axle_limit']}} lbs
ANALYZE:
1. What is the total weight and volume of all orders?
2. Can all orders fit in one vehicle?
3. What is the optimal loading sequence?
4. How should items be positioned for weight balance?
5. Are there any safety concerns?
RESPOND IN JSON:
{{
"total_orders": int,
"total_weight_lbs": float,
"total_volume_cuft": float,
"capacity_utilization_percent": float,
"can_fit_all": boolean,
"loading_sequence": [
{{
"order_id": "string",
"position": "string (e.g., 'rear left', 'center bottom')",
"stack_layer": int,
"loading_order": int,
"unloading_order": int
}}
],
"weight_distribution": {{
"front_axle_lbs": float,
"rear_axle_lbs": float,
"balance_score": float (0-100, 100=perfect balance)
}},
"safety_notes": ["array of important safety considerations"],
"optimization_score": float (0-100)
}}
"""
response = self.model.generate_content(planning_prompt)
load_plan = json.loads(response.text)
# Validate plan against DOT regulations
if not self.validate_dot_compliance(load_plan, vehicle_specs):
raise ValueError("Load plan violates DOT regulations")
return load_plan
def validate_dot_compliance(self, load_plan, vehicle_specs):
"""Ensure DOT compliance"""
checks = {
'weight_limit': load_plan['total_weight_lbs'] <= vehicle_specs['max_weight_lbs'],
'front_axle': load_plan['weight_distribution']['front_axle_lbs'] <= vehicle_specs['front_axle_limit'],
'rear_axle': load_plan['weight_distribution']['rear_axle_lbs'] <= vehicle_specs['rear_axle_limit'],
'balance': load_plan['weight_distribution']['balance_score'] >= 70
}
return all(checks.values())
def generate_3d_visualization(self, load_plan):
"""Generate 3D loading visualization"""
# Use Three.js or visualization library
pass
# Usage
optimizer = LoadPlanningOptimizer()
orders = [
{'id': 'ORD001', 'weight_lbs': 250, 'dimensions': [40, 30, 20], 'fragile': False, 'delivery_order': 3},
{'id': 'ORD002', 'weight_lbs': 100, 'dimensions': [20, 20, 15], 'fragile': True, 'delivery_order': 1},
{'id': 'ORD003', 'weight_lbs': 500, 'dimensions': [60, 40, 30], 'fragile': False, 'delivery_order': 2},
]
vehicle = {
'vehicle_id': 'VEH001',
'type': 'box_truck',
'max_weight_lbs': 10000,
'length': 240, # inches
'width': 96,
'height': 108,
'front_axle_limit': 4000,
'rear_axle_limit': 6000
}
load_plan = optimizer.optimize_load_plan(orders, vehicle)
print(json.dumps(load_plan, indent=2))
Outcome:
15-20% improvement in vehicle utilization
Reduction in number of trips required
Improved delivery efficiency
10. Cost Analytics & Budget Optimization - Advanced Analytics with BigQuery ML
Problem: Fleet managers lack visibility into cost drivers and optimization opportunities.
GCP Solution Architecture:
.png)
Implementation:
-- Comprehensive cost analytics model
CREATE OR REPLACE TABLE `fleet_ai.cost_analytics` AS
WITH daily_costs AS (
SELECT
DATE(timestamp) as date,
vehicle_id,
driver_id,
-- Fuel costs
SUM(fuel_consumed_gallons * fuel_price_per_gallon) as fuel_cost,
-- Maintenance costs
SUM(maintenance_cost) as maintenance_cost,
-- Labor costs
SUM(driver_hours * hourly_rate) as labor_cost,
-- Insurance (daily allocation)
(SELECT annual_premium / 365 FROM fleet_ai.insurance_policies WHERE vehicle_id = v.vehicle_id) as insurance_cost,
-- Depreciation (daily allocation)
(vehicle_purchase_price * 0.15) / 365 as depreciation_cost,
-- Operating metrics
SUM(distance_miles) as miles_driven,
SUM(deliveries_completed) as deliveries_completed,
AVG(vehicle_utilization_percent) as utilization_percent
FROM `fleet_ai.operations_data` v
GROUP BY date, vehicle_id, driver_id
),
cost_summary AS (
SELECT
*,
(fuel_cost + maintenance_cost + labor_cost + insurance_cost + depreciation_cost) as total_daily_cost,
(fuel_cost + maintenance_cost + labor_cost + insurance_cost + depreciation_cost) / NULLIF(miles_driven, 0) as cost_per_mile,
(fuel_cost + maintenance_cost + labor_cost + insurance_cost + depreciation_cost) / NULLIF(deliveries_completed, 0) as cost_per_delivery
FROM daily_costs
)
SELECT * FROM cost_summary;
-- Predictive cost model
CREATE OR REPLACE MODEL `fleet_ai.cost_prediction_model`
OPTIONS(
model_type='BOOSTED_TREE_REGRESSOR',
input_label_cols=['total_daily_cost'],
max_iterations=100
) AS
SELECT
vehicle_id,
driver_id,
EXTRACT(DAYOFWEEK FROM date) as day_of_week,
EXTRACT(MONTH FROM date) as month,
miles_driven,
deliveries_completed,
utilization_percent,
LAG(total_daily_cost, 1) OVER (PARTITION BY vehicle_id ORDER BY date) as prev_day_cost,
AVG(total_daily_cost) OVER (PARTITION BY vehicle_id ORDER BY date ROWS BETWEEN 7 PRECEDING AND 1 PRECEDING) as avg_weekly_cost,
total_daily_cost
FROM `fleet_ai.cost_analytics`
WHERE date >= DATE_SUB(CURRENT_DATE(), INTERVAL 1 YEAR);
-- Cost optimization recommendations
CREATE OR REPLACE TABLE `fleet_ai.cost_optimization_recommendations` AS
WITH vehicle_performance AS (
SELECT
vehicle_id,
AVG(cost_per_mile) as avg_cost_per_mile,
AVG(utilization_percent) as avg_utilization,
AVG(fuel_cost / NULLIF(miles_driven, 0)) as fuel_efficiency,
SUM(maintenance_cost) as total_maintenance_cost
FROM `fleet_ai.cost_analytics`
WHERE date >= DATE_SUB(CURRENT_DATE(), INTERVAL 90 DAY)
GROUP BY vehicle_id
),
fleet_averages AS (
SELECT
AVG(avg_cost_per_mile) as fleet_avg_cost_per_mile,
AVG(avg_utilization) as fleet_avg_utilization,
AVG(fuel_efficiency) as fleet_avg_fuel_efficiency
FROM vehicle_performance
)
SELECT
vp.vehicle_id,
vp.avg_cost_per_mile,
fa.fleet_avg_cost_per_mile,
-- Identify high-cost vehicles
CASE
WHEN vp.avg_cost_per_mile > fa.fleet_avg_cost_per_mile * 1.2 THEN 'HIGH_COST_VEHICLE'
WHEN vp.avg_cost_per_mile < fa.fleet_avg_cost_per_mile * 0.8 THEN 'EFFICIENT_VEHICLE'
ELSE 'AVERAGE'
END as cost_category,
-- Specific recommendations
ARRAY_AGG(
CASE
WHEN vp.avg_utilization < 60 THEN 'INCREASE_UTILIZATION - Vehicle is underutilized'
WHEN vp.fuel_efficiency > fa.fleet_avg_fuel_efficiency * 1.15 THEN 'FUEL_INVESTIGATION - Unusual fuel consumption'
WHEN vp.total_maintenance_cost > 5000 THEN 'CONSIDER_REPLACEMENT - High maintenance costs'
WHEN vp.avg_cost_per_mile > 2.50 THEN 'COST_REVIEW - Operating costs exceed targets'
END
IGNORE NULLS
) as recommendations,
-- Potential savings
(vp.avg_cost_per_mile - fa.fleet_avg_cost_per_mile) *
(SELECT AVG(miles_driven) FROM `fleet_ai.cost_analytics` WHERE vehicle_id = vp.vehicle_id) * 365
as potential_annual_savings
FROM vehicle_performance vp
CROSS JOIN fleet_averages fa
WHERE (vp.avg_cost_per_mile > fa.fleet_avg_cost_per_mile * 1.1
OR vp.avg_utilization < 60
OR vp.total_maintenance_cost > 5000)
ORDER BY potential_annual_savings DESC;
-- ROI analysis for fleet optimization initiatives
CREATE OR REPLACE TABLE `fleet_ai.optimization_roi` AS
SELECT
'Route Optimization' as initiative,
50000 as implementation_cost,
(SELECT SUM(fuel_cost) * 0.15 FROM `fleet_ai.cost_analytics` WHERE date >= DATE_SUB(CURRENT_DATE(), INTERVAL 1 YEAR)) as projected_annual_savings,
'Q1 2026' as implementation_timeline,
6 as payback_months
UNION ALL
SELECT
'Predictive Maintenance',
75000,
(SELECT SUM(maintenance_cost) * 0.25 + 150000 FROM `fleet_ai.cost_analytics` WHERE date >= DATE_SUB(CURRENT_DATE(), INTERVAL 1 YEAR)),
'Q2 2026',
4
UNION ALL
SELECT
'Driver Behavior Training',
25000,
(SELECT (SUM(fuel_cost) * 0.10) + 200000 FROM `fleet_ai.cost_analytics` WHERE date >= DATE_SUB(CURRENT_DATE(), INTERVAL 1 YEAR)),
'Q1 2026',
3;
Looker Studio Dashboard Integration:
# Generate dashboard export for Looker Studio
from google.cloud import bigquery
def generate_cost_dashboard_data():
client = bigquery.Client()
queries = {
'cost_overview': """
SELECT
DATE_TRUNC(date, MONTH) as month,
SUM(total_daily_cost) as total_cost,
SUM(fuel_cost) as fuel_cost,
SUM(maintenance_cost) as maintenance_cost,
SUM(labor_cost) as labor_cost,
AVG(cost_per_mile) as avg_cost_per_mile,
AVG(cost_per_delivery) as avg_cost_per_delivery
FROM `fleet_ai.cost_analytics`
WHERE date >= DATE_SUB(CURRENT_DATE(), INTERVAL 12 MONTH)
GROUP BY month
ORDER BY month DESC
""",
'vehicle_comparison': """
SELECT
vehicle_id,
AVG(cost_per_mile) as avg_cost_per_mile,
AVG(utilization_percent) as utilization,
SUM(miles_driven) as total_miles,
SUM(total_daily_cost) as total_cost
FROM `fleet_ai.cost_analytics`
WHERE date >= DATE_SUB(CURRENT_DATE(), INTERVAL 90 DAY)
GROUP BY vehicle_id
ORDER BY avg_cost_per_mile DESC
""",
'cost_predictions': """
SELECT
vehicle_id,
date,
predicted_total_daily_cost,
confidence_interval_lower,
confidence_interval_upper
FROM ML.PREDICT(MODEL `fleet_ai.cost_prediction_model`,
(SELECT * FROM `fleet_ai.operations_data`
WHERE date >= CURRENT_DATE()))
"""
}
results = {}
for name, query in queries.items():
results[name] = [dict(row) for row in client.query(query).result()]
return results
# Export to Google Sheets for Looker Studio
dashboard_data = generate_cost_dashboard_data()
# ... export logic
Outcome:
Complete visibility into cost drivers
10-15% overall cost reduction through data-driven decisions
Accurate budget forecasting
Clear ROI tracking for optimization initiatives
Data Pipeline Architecture
End-to-End Data Flow
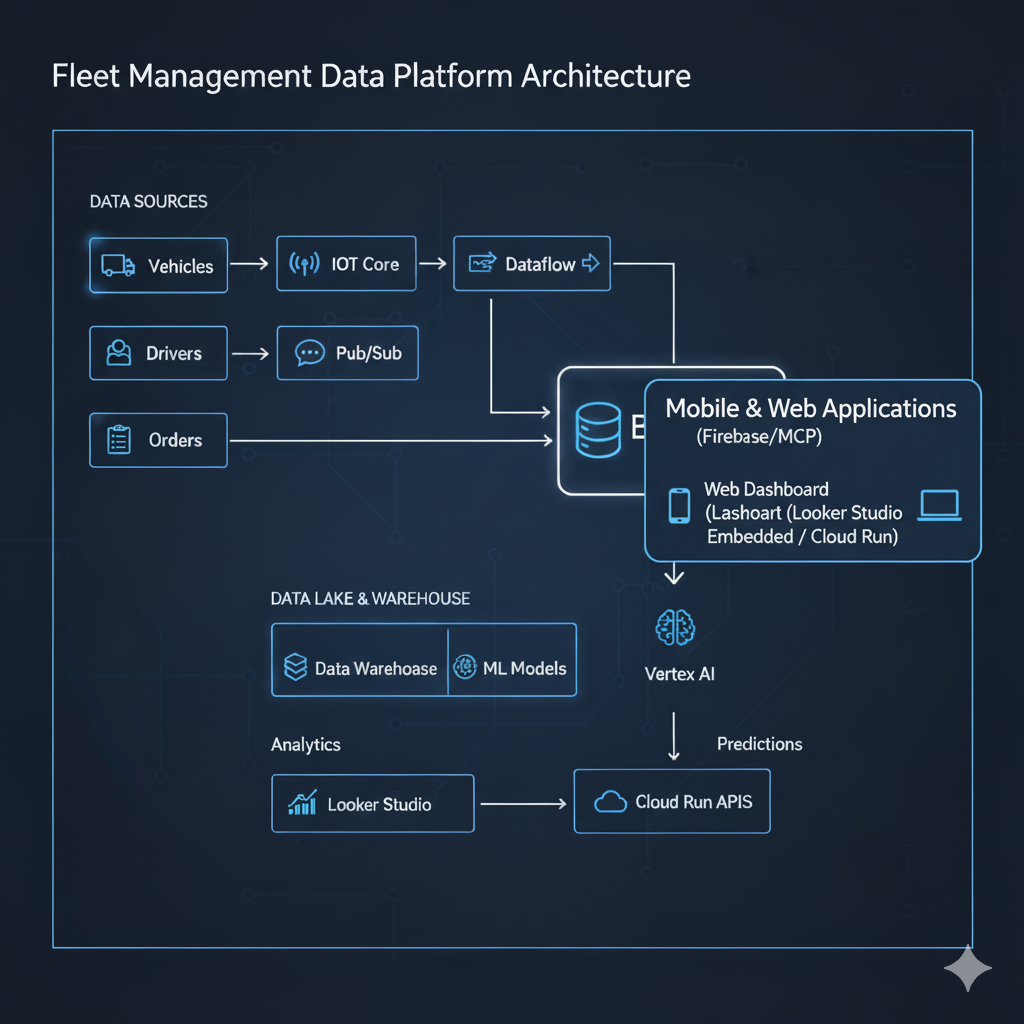
Data Processing Pipeline Code
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from google.cloud import bigquery
class ProcessTelemetry(beam.DoFn):
def process(self, element):
"""Transform raw telemetry data"""
import json
data = json.loads(element)
# Enrich with calculated fields
data['fuel_efficiency_mpg'] = data['miles_driven'] / data['fuel_consumed_gallons'] if data.get('fuel_consumed_gallons', 0) > 0 else 0
data['idle_percentage'] = (data['idle_time_seconds'] / data['total_trip_seconds']) * 100 if data.get('total_trip_seconds', 0) > 0 else 0
# Add processing timestamp
data['processed_at'] = datetime.utcnow().isoformat()
yield data
# Define Dataflow pipeline
def run_pipeline():
pipeline_options = PipelineOptions(
project='your-project-id',
runner='DataflowRunner',
region='us-central1',
streaming=True,
temp_location='gs://fleet-data/temp'
)
with beam.Pipeline(options=pipeline_options) as p:
# Read from Pub/Sub
telemetry = (p
| 'Read from Pub/Sub' >> beam.io.ReadFromPubSub(
subscription='projects/your-project-id/subscriptions/telemetry-sub'
)
| 'Process Telemetry' >> beam.ParDo(ProcessTelemetry())
)
# Write to BigQuery
telemetry | 'Write to BigQuery' >> beam.io.WriteToBigQuery(
table='fleet_ai.telemetry_processed',
schema='vehicle_id:STRING,timestamp:TIMESTAMP,fuel_efficiency_mpg:FLOAT,idle_percentage:FLOAT,...',
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND
)
if __name__ == '__main__':
run_pipeline()
Cost Analysis
Monthly Cost Estimate (100-Vehicle Fleet)
Service | Usage | Monthly Cost |
|---|---|---|
IoT Core | 100 devices, 1 msg/sec | $45 |
Pub/Sub | 250M messages/month | $120 |
Dataflow | 10 vCPUs, streaming | $720 |
BigQuery | 500GB storage, 10TB queries | $450 |
BigQuery ML | 10 models, 1000 predictions/day | $200 |
Vertex AI AutoML | 5 models | $300 |
Vertex AI Prediction | 100K predictions/month | $250 |
Gemini API | 10K requests/month (Pro) | $175 |
Cloud Storage | 2TB (dashcam footage) | $40 |
Cloud Run | 1M requests/month | $25 |
Cloud Functions | 2M invocations | $10 |
Cloud Vision API | 50K images/month | $75 |
Google Maps API | 100K requests/month | $700 |
Cloud Monitoring | Standard monitoring | $50 |
Total Estimated Monthly Cost: ~$3,160
Cost per Vehicle: ~$31.60/month
ROI Analysis
Savings from AI Implementation:
Area | Annual Savings (100 vehicles) |
|---|---|
Fuel optimization (15%) | $135,000 |
Maintenance cost reduction (25%) | $125,000 |
Accident reduction (40%) | $180,000 |
Route optimization (12% time) | $96,000 |
Improved utilization (20%) | $144,000 |
Total Annual Savings | $680,000 |
Annual GCP Cost: ~$37,920
Net Annual Benefit: $642,080
ROI: 1,693%
Payback Period: 0.7 months
Implementation Roadmap
Phase 1: Foundation (Weeks 1-4)
Goals:
Set up GCP project and IAM
Deploy data ingestion pipeline
Establish BigQuery data warehouse
Tasks:
Create GCP project and enable APIs
Configure IoT Core for vehicle connectivity
Set up Pub/Sub topics and subscriptions
Deploy Dataflow streaming pipeline
Create BigQuery datasets and tables
Implement basic monitoring
Deliverables:
Real-time telemetry flowing to BigQuery
Basic dashboards in Looker Studio
Data quality monitoring
Phase 2: Quick Wins (Weeks 5-8)
Goals:
Deploy 3 high-impact AI use cases
Demonstrate immediate value
Priority Use Cases:
Driver Behavior Monitoring (BigQuery ML classification)
Fuel Optimization (BigQuery ML regression)
Basic Route Optimization (Google Maps API integration)
Deliverables:
Driver risk scoring system
Fuel efficiency reports
Automated route suggestions
Expected Impact:
10-15% fuel savings
20% reduction in risky driving incidents
Phase 3: Advanced AI (Weeks 9-16)
Goals:
Deploy remaining AI capabilities
Implement agentic AI systems
Use Cases:
Predictive Maintenance (Vertex AI AutoML)
Demand Forecasting (Vertex AI time series)
Automated Dispatching (Gemini + Agent Builder)
Collision Prevention (Vision AI)
Deliverables:
Maintenance prediction system
Intelligent dispatch automation
Real-time safety alerts
Phase 4: Optimization & Scale (Weeks 17-24)
Goals:
Fine-tune models based on real-world performance
Scale to full fleet
Advanced analytics and reporting
Tasks:
Model retraining with production data
A/B testing of optimization strategies
Custom model development for unique use cases
Integration with existing fleet management systems
Comprehensive Looker Studio dashboards
Driver mobile app with AI-powered features
Deliverables:
Production-grade AI system
Executive dashboards
Mobile driver experience
Complete documentation
Phase 5: Continuous Improvement (Ongoing)
Goals:
Monitor performance and ROI
Regular model updates
New AI capability exploration
Activities:
Monthly model performance reviews
Quarterly business impact assessment
Continuous data quality monitoring
Exploration of emerging GCP AI features
Code Examples Repository
Example 1: Complete Dataflow Pipeline
# dataflow_pipeline.py - Complete streaming pipeline
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.transforms.window import FixedWindows
from datetime import datetime
import json
class EnrichTelemetry(beam.DoFn):
"""Enrich raw telemetry with calculated metrics"""
def process(self, element):
data = json.loads(element)
# Calculate metrics
enriched = {
'vehicle_id': data['vehicle_id'],
'timestamp': data['timestamp'],
'raw_metrics': data,
# Efficiency metrics
'mpg': self.calculate_mpg(data),
'idle_ratio': self.calculate_idle_ratio(data),
# Safety metrics
'harsh_events': self.count_harsh_events(data),
'speed_violations': self.count_speed_violations(data),
# Status
'health_score': self.calculate_health_score(data)
}
yield enriched
def calculate_mpg(self, data):
if data.get('fuel_consumed', 0) > 0:
return data['miles_driven'] / data['fuel_consumed']
return 0
def calculate_idle_ratio(self, data):
if data.get('total_time', 0) > 0:
return data['idle_time'] / data['total_time']
return 0
def count_harsh_events(self, data):
return (data.get('harsh_braking', 0) +
data.get('harsh_acceleration', 0) +
data.get('harsh_cornering', 0))
def count_speed_violations(self, data):
return data.get('speed_violations', 0)
def calculate_health_score(self, data):
# Simple health score calculation
score = 100
score -= data.get('engine_temp_deviation', 0) * 0.5
score -= data.get('oil_pressure_deviation', 0) * 0.3
score -= self.count_harsh_events(data) * 2
return max(0, min(100, score))
class DetectAnomalies(beam.DoFn):
"""Detect anomalies in telemetry data"""
def process(self, element):
anomalies = []
# Temperature anomaly
if element['raw_metrics'].get('engine_temp', 0) > 220:
anomalies.append({
'type': 'HIGH_TEMPERATURE',
'severity': 'CRITICAL',
'vehicle_id': element['vehicle_id'],
'timestamp': element['timestamp'],
'value': element['raw_metrics']['engine_temp']
})
# Low health score
if element['health_score'] < 70:
anomalies.append({
'type': 'LOW_HEALTH_SCORE',
'severity': 'WARNING',
'vehicle_id': element['vehicle_id'],
'timestamp': element['timestamp'],
'value': element['health_score']
})
# Excessive harsh events
if element['harsh_events'] > 10:
anomalies.append({
'type': 'EXCESSIVE_HARSH_EVENTS',
'severity': 'MEDIUM',
'vehicle_id': element['vehicle_id'],
'timestamp': element['timestamp'],
'value': element['harsh_events']
})
for anomaly in anomalies:
yield anomaly
def run():
pipeline_options = PipelineOptions(
streaming=True,
project='your-project-id',
region='us-central1',
temp_location='gs://fleet-data/temp',
staging_location='gs://fleet-data/staging'
)
with beam.Pipeline(options=pipeline_options) as p:
# Read telemetry from Pub/Sub
raw_telemetry = (p
| 'Read Telemetry' >> beam.io.ReadFromPubSub(
subscription='projects/your-project-id/subscriptions/telemetry-sub'
)
)
# Enrich telemetry
enriched = (raw_telemetry
| 'Enrich Data' >> beam.ParDo(EnrichTelemetry())
)
# Write enriched data to BigQuery
enriched | 'Write Enriched to BQ' >> beam.io.WriteToBigQuery(
table='fleet_ai.telemetry_enriched',
schema='vehicle_id:STRING,timestamp:TIMESTAMP,mpg:FLOAT,idle_ratio:FLOAT,...',
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND
)
# Detect and write anomalies
anomalies = (enriched
| 'Detect Anomalies' >> beam.ParDo(DetectAnomalies())
)
anomalies | 'Write Anomalies to BQ' >> beam.io.WriteToBigQuery(
table='fleet_ai.anomalies',
schema='type:STRING,severity:STRING,vehicle_id:STRING,timestamp:TIMESTAMP,value:FLOAT',
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND
)
# Publish critical anomalies back to Pub/Sub for alerting
(anomalies
| 'Filter Critical' >> beam.Filter(lambda x: x['severity'] == 'CRITICAL')
| 'Format for Pub/Sub' >> beam.Map(lambda x: json.dumps(x).encode('utf-8'))
| 'Publish Alerts' >> beam.io.WriteToPubSub(
topic='projects/your-project-id/topics/critical-alerts'
)
)
if __name__ == '__main__':
run()
Example 2: Cloud Functions for Alerting
# main.py - Cloud Function for processing alerts
from google.cloud import bigquery
from google.cloud import firestore
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
import json
import base64
def process_alert(event, context):
"""
Triggered by Pub/Sub message containing critical alert
"""
# Decode Pub/Sub message
pubsub_message = base64.b64decode(event['data']).decode('utf-8')
alert = json.loads(pubsub_message)
print(f"Processing alert: {alert['type']} for vehicle {alert['vehicle_id']}")
# Get vehicle and driver details
db = firestore.Client()
vehicle_ref = db.collection('vehicles').document(alert['vehicle_id'])
vehicle_doc = vehicle_ref.get()
if not vehicle_doc.exists:
print(f"Vehicle {alert['vehicle_id']} not found")
return
vehicle_data = vehicle_doc.to_dict()
driver_id = vehicle_data.get('current_driver_id')
# Send alert based on type and severity
if alert['severity'] == 'CRITICAL':
send_sms_alert(driver_id, alert)
notify_dispatcher(alert)
log_incident(alert)
elif alert['severity'] == 'WARNING':
send_push_notification(driver_id, alert)
log_incident(alert)
# Update vehicle status
vehicle_ref.update({
'last_alert': alert,
'last_alert_timestamp': firestore.SERVER_TIMESTAMP,
'alert_count': firestore.Increment(1)
})
def send_sms_alert(driver_id, alert):
"""Send SMS to driver"""
# Implementation using Twilio or similar
pass
def send_push_notification(driver_id, alert):
"""Send push notification via Firebase"""
from firebase_admin import messaging
message = messaging.Message(
notification=messaging.Notification(
title=f"⚠️ {alert['type']}",
body=f"Vehicle alert detected. Please check your dashboard."
),
data={
'alert_type': alert['type'],
'severity': alert['severity'],
'timestamp': alert['timestamp']
},
token=get_driver_device_token(driver_id)
)
response = messaging.send(message)
print(f"Push notification sent: {response}")
def notify_dispatcher(alert):
"""Send email to dispatcher for critical alerts"""
sender = "alerts@fleet.com"
recipient = "dispatcher@fleet.com"
message = MIMEMultipart()
message["From"] = sender
message["To"] = recipient
message["Subject"] = f"CRITICAL ALERT: {alert['type']} - Vehicle {alert['vehicle_id']}"
body = f"""
Critical Alert Detected
Vehicle ID: {alert['vehicle_id']}
Alert Type: {alert['type']}
Severity: {alert['severity']}
Timestamp: {alert['timestamp']}
Value: {alert.get('value', 'N/A')}
Immediate action required.
"""
message.attach(MIMEText(body, "plain"))
# Send email (configure SMTP settings)
# smtp_server = smtplib.SMTP('smtp.gmail.com', 587)
# ...
def log_incident(alert):
"""Log incident to BigQuery for analysis"""
client = bigquery.Client()
table_id = "fleet_ai.incident_log"
rows_to_insert = [{
'vehicle_id': alert['vehicle_id'],
'alert_type': alert['type'],
'severity': alert['severity'],
'timestamp': alert['timestamp'],
'value': alert.get('value'),
'processed_at': datetime.utcnow().isoformat()
}]
errors = client.insert_rows_json(table_id, rows_to_insert)
if errors:
print(f"Errors inserting rows: {errors}")
def get_driver_device_token(driver_id):
"""Get FCM device token for driver"""
db = firestore.Client()
driver_doc = db.collection('drivers').document(driver_id).get()
if driver_doc.exists:
return driver_doc.to_dict().get('fcm_token')
return None
Conclusion
Key Takeaways
Implementing AI-powered fleet management on Google Cloud Platform offers:
Unified Platform : All AI capabilities (no-code, custom ML, LLMs) in one ecosystem
Rapid Development : BigQuery ML and Vertex AI AutoML enable quick POCs
Scalability : Serverless architecture scales from pilot to enterprise
Cost-Effective : Pay-per-use model with predictable costs
Comprehensive : Covers all 10 critical fleet management AI use cases
Success Metrics to Track
Operational Metrics:
Fleet utilization rate (target: >75%)
On-time delivery rate (target: >95%)
Average cost per mile (track 15-20% reduction)
Preventable accidents (target: 50% reduction)
Unplanned maintenance events (target: 40% reduction)
Financial Metrics:
Total operating costs
Fuel costs per mile
Maintenance cost per vehicle
Insurance premiums
ROI on AI investment
AI Performance Metrics:
Model accuracy (>85% for critical models)
Prediction latency (<500ms)
Data pipeline uptime (>99.9%)
False positive rate for alerts (<10%)
Next Steps
Start Small : Begin with 10-20 vehicle pilot
Focus on Quick Wins : Implement driver behavior and fuel optimization first
Iterate Based on Data : Use first 30 days to refine models
Scale Gradually : Expand to full fleet after validation
Continuous Learning : Retrain models monthly with new data
Resources
GCP Documentation:
